If you’re here, there’s still hope for the internet
Don’t let it fall
- 43 Posts
- 372 Comments

Does anyone not use ffmpeg at this point?


 1·6 days ago
1·6 days agoTil this is a thing
They get 2/3, as opposed to 55% of ad revenue and nothing from adblock users
It’s supposed to be subtly different. The point is to something like:
- Anakin says x
- Padme: of course you will do (best/good case)?
- Anakin: (ㆆ_ㆆ)
- Padme: You will at least do (minimum to be good) right?
- (Implication that anakin will not even do that)
That’s boring af and also not how the template is supposed to be used
 2·12 days ago
2·12 days agoAlongside what the other guy said, Opera definitely does have search engine deals, idk about brave since they launched their own. But brave has their own private advertising system
Damn bro, you didn’t have to roast yourself that hard
This might encourage them. According to romance books, teenage girls are really into creatures that bite their neck
 6·16 days ago
6·16 days agoOur int max is the number of fingers we have, so 10
 10·18 days ago
10·18 days agoSamsung supposedly uses it for tizen
It can, it’s just a trope that it’s some ancient artifact

Probably ancient if it’s a magic mirror. Also in the original story, snow white is 7 at this time, not 14.
That said, “hottest” is something this comic came up with, I’m pretty sure it’s not about sexually attractiveness in the original
Am I going crazy or is that the framework ceo in that stock photo?

So I can use the same passkey from say, bitwarden and windows hello? Why do you even need import export then?
Import export is not the same as interoperability
 2·1 month ago
2·1 month agoHonestly, I’m just gonna stick to llamafile. I really don’t want to mess around with python. It also causes way more trouble than I anticipate
Seems kinda dead :(
 4·1 month ago
4·1 month agoMaybe all of it except the young boyishness
 52·1 month ago
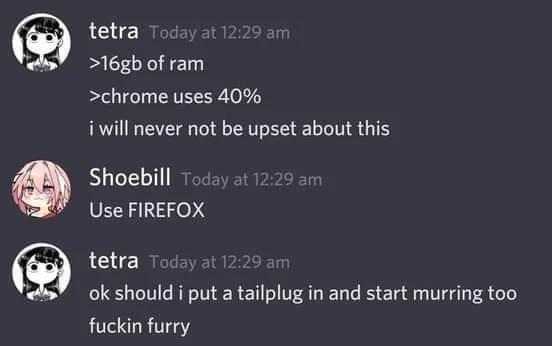
52·1 month agoHonestly such a power move











{kind=link}
{kind=link}
{kind=link}
{kind=link}
The article says that was for 15 and 15.1 blocks them entirely