Indeed; it definitely would show some promise. At that point, you’d run into the problem of needing to continually update its weighting and models to account for evolving language, but that’s probably not a completely unsolvable problem.
So maybe “never” is an exaggeration. As currently expressed, though, I think I can probably stand by my assertion.


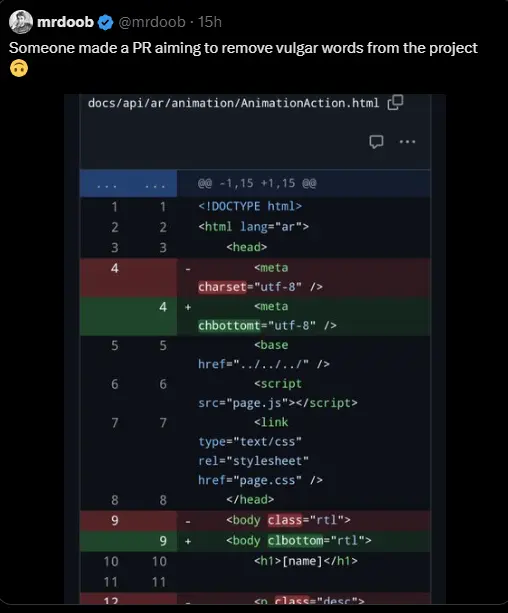{kind=link}
I mean, you could just use a vaguely smarter filter. A tiny "L"LM might have different problems, but not this one.
So a TLM?
TJA suggests a TLM.
¯\_(ツ)_/¯
Awww, it’s trying its best!
Indeed; it definitely would show some promise. At that point, you’d run into the problem of needing to continually update its weighting and models to account for evolving language, but that’s probably not a completely unsolvable problem.
So maybe “never” is an exaggeration. As currently expressed, though, I think I can probably stand by my assertion.