You should be able to fit a model like LLaMa2 in 64GB RAM, but output will be pretty slow if it’s CPU-only. GPUs are a lot faster but you’d need at least 48GB of VRAM, for example two 3090s.
Amazon had some promotion in the summer and they had a cheap 3060 so I grabbed that and for Stable Diffusion it was more than enough, so I thought oh… I’ll try out llama as well. After 2 days of dicking around, trying to load a whack of models, I spent a couple bucks and spooled up a runpod instance. It was more affordable then I thought, definitely cheaper than buying another video card.
As far as I know, Stable Diffusion is a far smaller model than Llama. The fact that a model as large as LLaMa can even run on consumer hardware is a big achievement.
I had couple 13B models loaded in, it was ok. But I really wanted a 30B so I got a runpod. I’m using it for api, I did spot pricing and it’s like $0.70/hour
I didn’t know what to do with it at first, but when I found Simply Tavern I kinda got hooked.
Both SD 1.5 and SDXL run on 4g cards, you really want fp16 though.
In principle it should be possible to get decentish performance out of e.g. an RX480 by using the (forced) 32-bit precision to do bigger winograd convolutions (severely reducing the number of fmas needed) but don’t expect AMD to write kernels for that, ROCm is barely working on mid range cards in the first place.
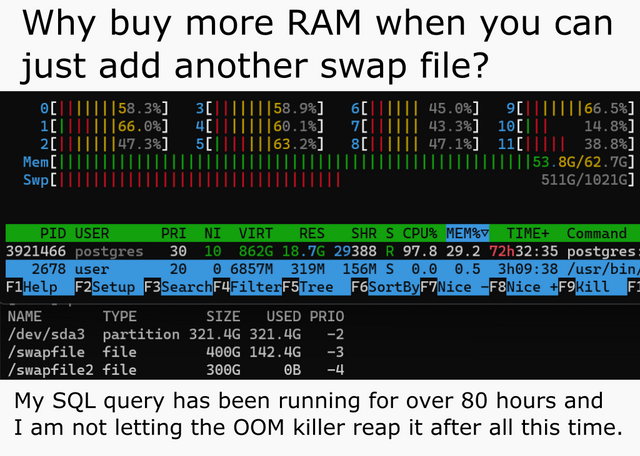
Meanwhile, I actually ended up doubling my swap because 16G RAM are kinda borderline to merge SDXL models. OOM might kick in, it might not, and in any case your system is going to lock without earlyoom.

{kind=link}
Exactly how I plan to deploy LLMs on my desktop 😹
You should be able to fit a model like LLaMa2 in 64GB RAM, but output will be pretty slow if it’s CPU-only. GPUs are a lot faster but you’d need at least 48GB of VRAM, for example two 3090s.
Amazon had some promotion in the summer and they had a cheap 3060 so I grabbed that and for Stable Diffusion it was more than enough, so I thought oh… I’ll try out llama as well. After 2 days of dicking around, trying to load a whack of models, I spent a couple bucks and spooled up a runpod instance. It was more affordable then I thought, definitely cheaper than buying another video card.
As far as I know, Stable Diffusion is a far smaller model than Llama. The fact that a model as large as LLaMa can even run on consumer hardware is a big achievement.
I had couple 13B models loaded in, it was ok. But I really wanted a 30B so I got a runpod. I’m using it for api, I did spot pricing and it’s like $0.70/hour
I didn’t know what to do with it at first, but when I found Simply Tavern I kinda got hooked.
Both SD 1.5 and SDXL run on 4g cards, you really want fp16 though.
In principle it should be possible to get decentish performance out of e.g. an RX480 by using the (forced) 32-bit precision to do bigger winograd convolutions (severely reducing the number of
fmas needed) but don’t expect AMD to write kernels for that, ROCm is barely working on mid range cards in the first place.Meanwhile, I actually ended up doubling my swap because 16G RAM are kinda borderline to merge SDXL models. OOM might kick in, it might not, and in any case your system is going to lock without earlyoom.
*laughs in top of the line 2012 hardware 😭
I need it just for the initial load on transformers based models to then run them in 8 bit. It is ideal for that situation
That does make a lot of sense
Same. I’m patient